
Donderdag was SAP down. Dus paniek in de tent, red-alert, rennen, stress?
Nou nee, dat was vroeger…
Een aantal jaar geleden, pak ‘m beet vijf, was het inderdaad stressen als het administratieve en logistieke systeem SAP down was. Ik herinner me dat nog goed. Want de webapplicaties die data uit SAP gebruikten, konden daar niet zo goed tegen. En server’s liepen uit het geheugen en kwamen tot stilstand. Dus gingen we rennen en vliegen: klanten en gebruikers informeren, toegang dichtzetten, server’s herstarten. En sommige managers schrokken dan ook best wel, dus veel uitleggen en “gedoe” achteraf. Het geschonden vertrouwen weer terugwinnen.
Relax
Maar donderdag was het anders. Heel anders!
De IT-teams hoefden eigenlijk niets te doen. Alleen maar afwachten. Relaxt!
Want de applicaties en microservices die we nu hebben, zijn modern. Die schrikken niet meer zo makkelijk van een hick-up. Ze wachten rustig af tot een haperend systeem zoals SAP er weer is. Ze vragen af en toe vriendelijk bij het slachtoffer of het alweer een beetje gaat. Bovendien melden de moderne applicaties zelf dat er problemen zijn, en vragen gebruikers het later nog eens te proberen.
Mooiste voorbeeld vond ik wel dat de Gilde bijeenkomst van Java ontwikkelaars gewoon door kon gaan tijdens de SAP-storing. Vijf jaar geleden had dat absoluut niet gekund…
Mooi spul dat Service Mesh
En nog indrukwekkender vond ik wel Gijs van Dulmen’s praatje over OpenShift Shift Service Mesh. Hiermee liet hij live zien hoe relaxt de applicaties met de storing omgingen: Je zag live alle dataverkeer, de storingen daarin en de gezondheid van de apps en microservices.
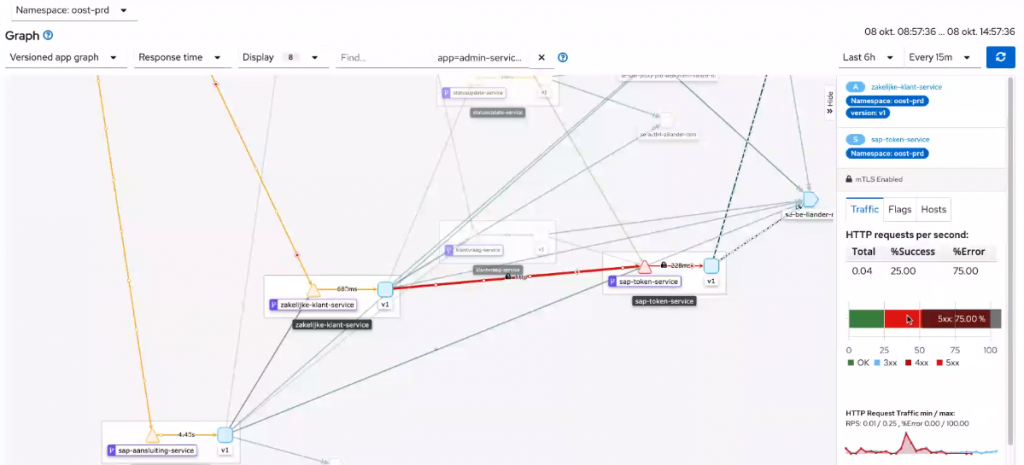
Mooi spul!
Proof of the pudding
Ik weet natuurlijk wel dat binnen het bedrijf de SAP downtijd zorgde voor overlast. En dat andere IT-collega’s er druk mee zijn geweest. Maar ikzelf was stiekem erg blij, toen ik zag dat de zero-ops architectuur met zelfinformerende en zelfherstellende apps en microservices het aardig goed bleek te doen! En voor de teams was het een mooi leermoment om nog wat zaken verder te verbeteren. Zoals het wellicht verder automatiseren van enkele handmatige acties en aanpassen van een erg relaxt ingesteld ritme van zelfherstelling.
Ik ben benieuwd: hoe zelfinformerend en zelfherstellend zijn jouw applicaties? En waar loop je tegenaan om dergelijke zero-ops oplossingen voor elkaar te krijgen?
Laat het weten in de reacties!
 Op deze site schrijf ik over mijn tips en ervaringen voor een betere wereld. Lees over Duurzaamheid, Architectuur, Geluk & Gezondheid en Openbaar Vervoer.
Op deze site schrijf ik over mijn tips en ervaringen voor een betere wereld. Lees over Duurzaamheid, Architectuur, Geluk & Gezondheid en Openbaar Vervoer.